

HUB-AND-SPOKE MPLS L3VPNs – ADVANCED CUSTOMISATION, ON JUNIPER JUNOS ROUTERS
Hey, do you remember two weeks ago when we first learned about hub-and-spoke MPLS VPNs? I do. I remember it, almost as if it was yesterday. Which it wasn’t: it was two weeks ago. Still though, doesn’t it seem like it was only yesterday? No.
Anyway, forget I said any of that: in our first post we learned how to “do it” with two interfaces between the hub PE (Provider Edge) and the hub CPE (Customer Premises Equipment). Often folks call it the CPE (Customer Edge), but I get really confused between PE and CE when I skim-read things, so I like to say CPE instead.
In part two we learned how to “get it going” with just one interface, and teach our hub CPE to only advertise a default route to the spokes. If you haven’t read those first two posts yet, give them a click, and come back to this one another day, because in this post we’ll be taking all that knowledge and building on it with some advanced features!
So far all our examples have been very clean, with no competing protocols messing things up. That’s the beauty of the lab! But of course, in the real world there’s inevitably going to be all sorts of extra “knobs” in the way, if you know what I mean. Hey, I’m just talking about nerd knobs, my guy! Nerd knobs! Nerd knobs. There’s nothing weird or funny about the phrase. Let’s take a moment to think about nerd knobs.
Anyway, once again forget I said that: this post is dedicated to just some of the many gotchas that come about when you’re running a real-world hub-and-spoke MPLS VPN, with BGP between hub PE and hub CPE. We’ll see how these gotchas break the network – and, because I love you very much indeed, we’ll see how to fix it.
A QUICK SUMMARY OF WHAT WE’VE DONE SO FAR
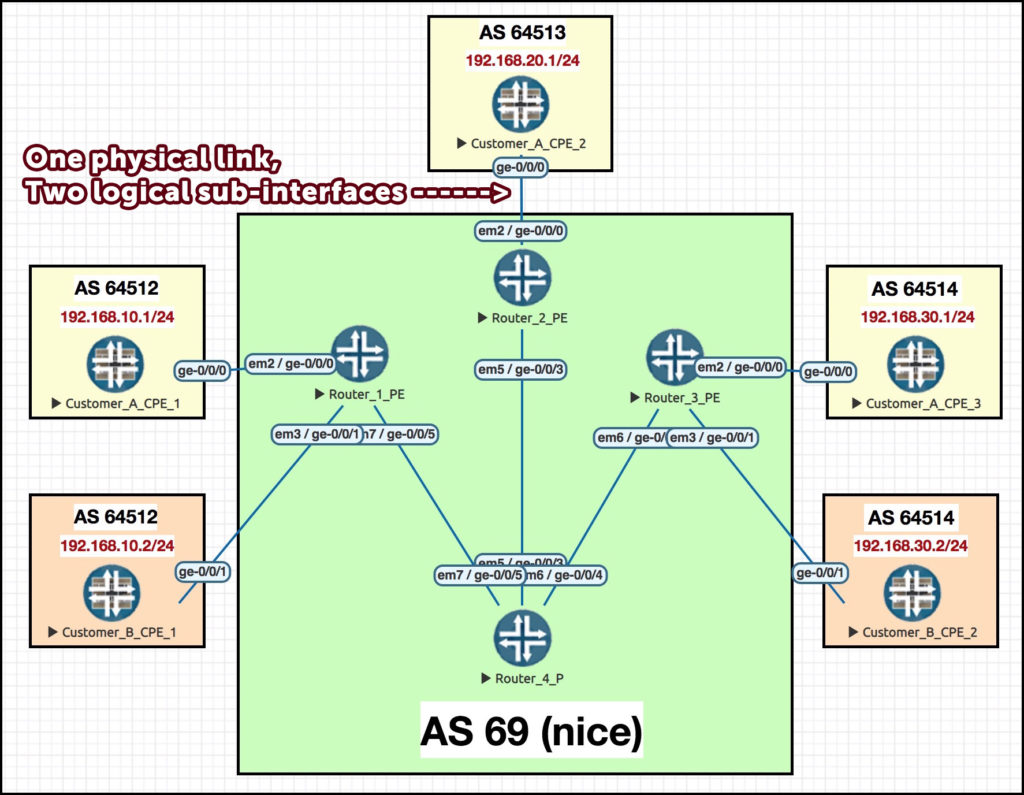
Here’s our sweet topology. You’ll remember that Customer A has three sites, of which there’s two spokes and one hub (CPE_2). You’ll see below that we’re back to the two-interface topology that we saw in Part 1. At the end of that post I shared the full config for every single router in the lab. If you want to follow along, feel free to use this file as your base config, or just give it a read to get a feel for what we’ve done on each router so far.
As always, I highly recommend opening up this diagram in a new tab, so you can easily switch back to it as you read this post. Give it a click:
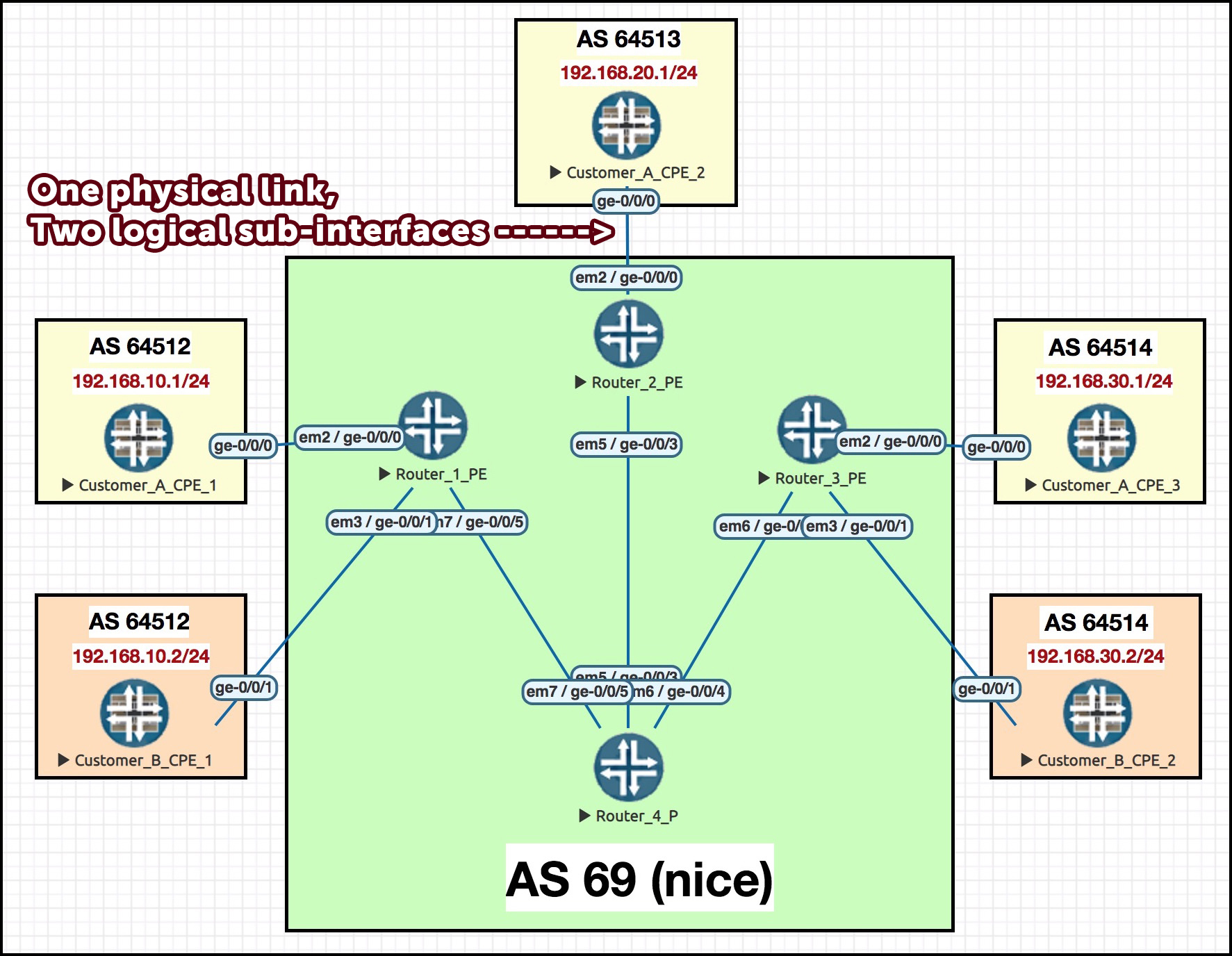
Each customer site is running BGP between the PE and CPE. Notice that each site is currently in its own unique private autonomous system. At various points in this post we’ll be changing that, so that all three sites are in AS64512.
We’ve learned already that hub-and-spoke MPLS VPNs need a few commands more than the usual full-mesh MPLS VPNs that we’re familiar with. For example, in our first post we had to configure “autonomous-system loops 2” on the PEs to allow for the fact that our ISP’s autonomous system appears multiple times in the path, as prefixes go through the ISP to the hub CPE, then back through the ISP again before they arrive at the spoke CPEs.
With all that in mind, let’s jump in and see what extra commands we can add, and what the consequences are.
One final thing: you’ll see in this diagram that there’s actually two customers. We don’t use the second customer in this post; I include it so that if you lab it up yourself then you can test that the traffic truly is staying within the customer’s own VRF, and not leaking out to other customers. Merry Christmas!
PROBLEM ONE: BGP BETWEEN PE AND CE, SAME AUTONOMOUS SYSTEM AT ALL SITES
It’s very common to configure all the sites for a MPLS VPN customer to use the same autonomous system. But does it cause problems with hub-and-spoke topologies? Yep!
Let’s temporarily change our topology so that all of customer A’s sites are in AS64512. CPE 1 is already in the right AS, so let’s do this on CPEs 2 and 3:
[edit] root@CUSTOMER_A_CPE_3# set routing-options autonomous-system 64512
We’ll also need to change the config on the PE routers so that they’re peering with the correct new customer AS. So, let’s add this command on PE Router 3. Similar commands are entered on the two hub peerings at PE2.
[edit] root@Router_3_PE# set routing-instances CUSTOMER_A protocols bgp group CUSTOMER_A_CPE_3 peer-as 64512
Now, in our first blog we configured advertise-peer-as onto the hub CPE 2, because this command turns on the ability to take a prefix from one AS and then re-advertise it back to the same AS. And if you think about it, that’s exactly what our Provider Edge routers now need to do: they need to take prefixes from a spoke peer in AS64512, and advertise them to a different peer (the hub) that’s also in AS64512.
Let’s think about CPE 1’s LAN range, 192.168.10.0/24. Our Provider Edge router PE1 advertises this to the route reflector, who then advertises it to PE2. PE2 can see that this prefix originated from AS 64512:
root@Router_2_PE> show route table VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB.inet.0 192.168.10.0/24 VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB.inet.0: 6 destinations, 8 routes (6 active, 0 holddown, 2 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.0/24 *[BGP/170] 00:05:52, localpref 100, from 4.4.4.4 AS path: 64512 I, validation-state: unverified > to 10.10.24.4 via ge-0/0/3.0, Push 299824, Push 299808(top)
PE2 peers with the hub CPE, which is now also in AS64512. And so, by default, this LAN range at CPE 1 is not re-advertised to different routers in the same AS.
Let’s look at what PE2 is advertising to 10.10.250.101, which is one of the IP addresses of the hub CPE. Notice below that PE2 is only advertising the two /31 ranges that connect the spokes to their PE routers. Despite the fact that we’re advertising the PE_1-to-CPE_1 /31 link, the CPE 1 LAN range itself is nowhere to be seen.
root@Router_2_PE> show route advertising-protocol bgp 10.10.250.101 VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB.inet.0: 6 destinations, 8 routes (6 active, 0 holddown, 2 hidden) Prefix Nexthop MED Lclpref AS path * 10.10.250.0/31 Self I * 10.10.250.6/31 Self I
Luckily, the fix is easy. Let’s add this one magic command. We’ll need this in the Customer A VRF on PEs 1 and 3, plus the exporting-to-the-hub VRF at PE2:
[edit] root@Router_2_PE# set routing-instances VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB protocols bgp group CUSTOMER_A_CPE_2 advertise-peer-as
Let’s see what the hub PE2 is now advertising to the hub CPE:
root@Router_2_PE> show route advertising-protocol bgp 10.10.250.101 VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB.inet.0: 6 destinations, 10 routes (6 active, 0 holddown, 4 hidden) Prefix Nexthop MED Lclpref AS path * 10.10.250.0/31 Self I * 10.10.250.6/31 Self I * 192.168.10.0/24 Self 64512 I * 192.168.30.0/24 Self 64512 I
Excellent! We’re making progress – but we’re not done yet.
The other thing we did in our first post was to configure our ISP’s PE routers to accept loops, because the ISP is going to see its own AS, 69 (nice), in the path. This time we need to do the same thing on our CPEs, because they’re all going to see AS64512 in the path: once at the hub, and twice at the spokes. For ease in our lab we add the same config on CPEs 1, 2 and 3:
[edit] root@CUSTOMER_A_CPE_3> set routing-options autonomous-system loops 3
And after that, CPE 3 successfully receives everything, including 192.168.10.0/24. Let’s see what CPE 3 is receiving from 10.10.250.6, the address of its PE router:
root@CUSTOMER_A_CPE_3> show route receive-protocol bgp 10.10.250.6 inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 10.10.250.0/31 10.10.250.6 69 64512 69 I * 10.10.250.100/31 10.10.250.6 69 64512 I * 10.10.250.102/31 10.10.250.6 69 I * 192.168.10.0/24 10.10.250.6 69 64512 69 64512 I * 192.168.20.0/24 10.10.250.6 69 64512 I
Happy happy days!
The fix on this one was easy: it just involved using commands we’ve already learned. Now let’s look at a new problem, and a new solution.
PROBLEM TWO: USING AS-OVERRIDE TO HIDE OUR CUSTOMER’S PRIVATE AS NUMBER
Let’s keep all three of Customer A’s sites live in the same autonomous system, AS64512.
As we learned a moment ago, we now have two possible places that AS-PATH loops can occur:
- First, prefixes get advertised from the customer’s AS64512 at a source spoke; the prefixes then come in and then go out again from AS64512 at the hub site; and then the prefixes finally land once again in an AS64512, at the destination spoke.
- Second, prefixes transit through our ISP’s AS69 (nice) twice, due to all traffic going out from the ISP to the hub, and back into the ISP again.
And as we all learned when we were only two years old, when BGP sees loops, it ignores the prefixes.
So far we’ve fixed it by allowing loops on the various routers. In doing so we’ve kept the full AS-PATH unchanged.
There’s an alternative way to fix it: allow loops in the ISP’s network, and remove the customer’s private AS as the prefix goes from site to site. How? Using the as-override command. This command strips the customer’s AS number, and replaces it with the ISP’s AS.
Let’s once again follow CPE 1’s LAN, 192.168.10.0/24, to see the result of this new and exciting config. How is the hub CPE is currently advertising this prefix back to PE2?
root@CUSTOMER_A_CPE_2> show route advertising-protocol bgp 10.10.250.102 192.168.10.0/24 inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 192.168.10.0/24 Self 69 64512 I
The AS path is clear: it starts in the customer’s AS64512, and then goes through our ISP, AS69 (nice).
So, how do we hide AS64512 from the path? Let’s add the following configuration to all three PE routers:
[edit] root@Router_1_PE# set routing-instances CUSTOMER_A protocols bgp group CUSTOMER_A_CPE_1 as-override
[edit] root@Router_2_PE# set routing-instances VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB protocols bgp group CUSTOMER_A_CPE_2 as-override
[edit] root@Router_3_PE# set routing-instances CUSTOMER_A protocols bgp group CUSTOMER_A_CPE_3 as-override
And once it’s committed, what does the hub CPE now see in the AS-path for this prefix?
root@CUSTOMER_A_CPE_2> show route advertising-protocol bgp 10.10.250.102 192.168.10.0/24 inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 192.168.10.0/24 Self 69 69 I
Look at that: the AS-PATH has been overwritten, and replaced with the ISP’s AS. “Nice”!
We’ll also need to adjust the loops allowed on our PE routers, because previously we were only allowing two loops. To be clear, PE2 won’t officially add AS69 into the path for a third time until the prefix leaves AS69 again. But still, PE2 knows that AS69 appears twice, and that the prefix is coming into AS69 a third time. As such, it rejects the prefix. We can see this by looking in the routing table for the hub-to-spoke VRF:
root@Router_2_PE> show route table VRF_CUSTOMER_A_HUB_ADVERTISING_TO_SPOKES.inet.0 192.168.10.0/24 root@Router_2_PE>
The fix? We just need to allow one extra loop on all our PE routers. Here’s the config at PE 2. Similar config is added at PEs 1 and 3:
[edit] root@Router_2_PE# set routing-options autonomous-system 69 loops 3
We give our BGP a quick clearing (aah, the luxury of the lab!), and then… we see success!
root@Router_2_PE> clear bgp neighbor 10.10.250.103 root@Router_2_PE> show route table VRF_CUSTOMER_A_HUB_ADVERTISING_TO_SPOKES.inet.0 192.168.10.0/24 VRF_CUSTOMER_A_HUB_ADVERTISING_TO_SPOKES.inet.0: 8 destinations, 9 routes (8 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.0/24 *[BGP/170] 00:00:03, localpref 100 AS path: 64512 69 69 I, validation-state: unverified > to 10.10.250.103 via ge-0/0/0.20
The result is that CPE 3 can ping CPE 1 again. Notice below that AS69 actually appears four times. Remember, the two previous appearances of AS64512 are being replaced wtih the ISP’s AS. However, we don’t need to allow four loops at the customer CPE, because it’s a totally different AS. As far as AS64512 is concerned, there can be as many loops in AS69 as you like, within the limits of the router’s hardware, the rules of BGP, and most importantly the rules of the universe:
root@CUSTOMER_A_CPE_3> ping 192.168.10.1 PING 192.168.10.1 (192.168.10.1): 56 data bytes 64 bytes from 192.168.10.1: icmp_seq=0 ttl=57 time=46.556 ms {snip} root@CUSTOMER_A_CPE_3> show route 192.168.10.1 inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.0/24 *[BGP/170] 00:02:12, localpref 100 AS path: 69 69 69 69 I > to 10.10.250.6 via ge-0/0/0.0
PROBLEM THREE: SITE OF ORIGIN, AKA ROUTE ORIGIN, AKA THE ORIGIN COMMUNITY
There’s a problem with a hub-and-spoke MPLS VPN topology: spoke prefixes might get re-advertised back to the same spokes that originated them.
Once again focusing on CPE 1’s LAN, 192.168.10.0/24, let’s take a look at what PE1 is learning. Notice that it knows about CPE 1’s LAN from two different sources. The top route in the output below is from PE1’s directly-connected CPE. This is the “good” route. The bottom route is from the hub PE, advertising it right back to PE1 again, even though it came from PE1 in the first place.
root@Router_1_PE> show route table CUSTOMER_A 192.168.10.0/24 CUSTOMER_A.inet.0: 8 destinations, 11 routes (8 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.0/24 *[BGP/170] 00:38:11, localpref 100 AS path: 64512 I, validation-state: unverified > to 10.10.250.1 via ge-0/0/0.0 [BGP/170] 00:09:14, localpref 100, from 4.4.4.4 AS path: 64512 69 69 I, validation-state: unverified > to 10.10.14.4 via ge-0/0/5.0, Push 299888, Push 299808(top)
If the CPE 1 WAN link were to go down, we could for a short while have ourselves a routing loop, until BGP re-converges. It would be very brief, but still, if avoiding loops at all costs is your priority, you’ll want to filter these out. How? By using the site of origin community. Ever heard of it? All the kids are using it. It’s very fashionable. Maybe you should use it too. Unless you’re a square?
Let’s define a new site-of-origin community on the customer’s router, CPE 1.
[edit] root@CUSTOMER_A_CPE_1# set policy-options community ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1 members origin:64512:1
Now, let’s take our existing BGP export policy on the customer’s router, and slip in this extra line:
[edit]
root@CUSTOMER_A_CPE_1# set policy-options policy-statement EXPORT_CONNECTED then community add ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1
Now when CPE1’s export policy redistributes all its directly connected prefixes, the router adds this site-of-origin community. Here’s how CPE1’s export policy looks after our change:
root@CUSTOMER_A_CPE_1> show configuration policy-options policy-statement EXPORT_CONNECTED { from protocol direct; then { community add ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1; accept; } } community ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1 members origin:64512:1;
PE1 now sees these prefixes from CPE1 with this community attached:
root@Router_1_PE# show route receive-protocol bgp 10.10.250.1 table CUSTOMER_A.inet.0 192.168.10.0/24 extensive CUSTOMER_A.inet.0: 8 destinations, 11 routes (8 active, 0 holddown, 0 hidden) * 192.168.10.0/24 (2 entries, 1 announced) Accepted Nexthop: 10.10.250.1 AS path: 64512 I Communities: origin:64512:1
Juniper routers don’t strip communities as prefixes pass from autonomous system to autonomous system. As such, this community will stay on the prefix for as long as it travels around the network. Other vendors do indeed strip these communities, so bear that in mind if you’re in a multi-vendor environment!
 Now, let’s be clear on the path this BGP prefix takes:
Now, let’s be clear on the path this BGP prefix takes:
- It starts at CPE 1, and goes to PE1.
- From PE1 it goes to the route reflector (Router_4_P), and then to PE2.
- From there it goes to the hub CPE, and then back to PE2 again.
- PE2 sends it once again to the route reflector again.
- And finally, the route reflector sends it back to all the spoke PEs – including PE 1.
With that in mind, now that we’re adding this site-of-origin community, let’s look at how PE1 sees the LAN prefix once it’s gone through the hub and back.
If we look at what PE1 is learning from the route reflector, we see three communities. First, the hub-to-spoke community that PE2 will have added. Second, the spoke-to-hub community, because this isn’t stripped by default. But most importantly for us right now, we still see the site-of-origin community that CPE1 added on!
root@Router_1_PE# show route receive-protocol bgp 4.4.4.4 table CUSTOMER_A.inet.0 192.168.10.0/24 extensive CUSTOMER_A.inet.0: 8 destinations, 11 routes (8 active, 0 holddown, 0 hidden) 192.168.10.0/24 (2 entries, 1 announced) Import Accepted Route Distinguisher: 2.2.2.2:2 VPN Label: 299888 Nexthop: 2.2.2.2 Localpref: 100 AS path: 64512 69 69 I (Originator) Cluster list: 4.4.4.4 Originator ID: 2.2.2.2 Communities: target:69:100 target:69:200 origin:64512:1
So, how do we stop PE1 accepting 192.168.10.0/24 back from the hub? There’s a few ways:
— You might be tempted to think that we could forget about all this site-of-origin stuff, and just block any prefix with the spoke-to-hub community (target:69:100). After all, aren’t we only supposed to be importing prefixes from the hub? However, remember that every prefix from every spoke will have this community attached, because it isn’t stripped, so if you do that you’ll block almost everything!
— And it’s no use removing this target community at the hub, because it won’t stop CPE1’s LAN from still being re-advertised back to PE1.
— The third, and best, option is to add a policy on PE1 that blocks any prefixes from the route reflector with this site of origin community (origin:64512:1).
Let’s define the community at PE1:
set policy-options community ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1 members origin:64512:1
Now let’s write a policy that blocks anything with this community. In a moment we’ll attach this policy to the peering with the route reflector.
set policy-options policy-statement DROP_LOOPED_SITE_OF_ORIGIN_PREIFXES from community ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1 set policy-options policy-statement DROP_LOOPED_SITE_OF_ORIGIN_PREIFXES then reject
Let’s add this new policy as an import rule on PE1’s route reflector peering. Remember, the default behaviour of BGP is to accept everything, so although we haven’t explicitly told this policy to accept everything else, any prefix that doesn’t have this site-of-origin community will still be accepted.
set protocols bgp group AS69 import DROP_LOOPED_SITE_OF_ORIGIN_PREIFXES
We give it a sweet commit, and then we check again how PE1 is learning about 192.168.10.0/24:
root@Router_1_PE> show route table CUSTOMER_A 192.168.10.0/24 CUSTOMER_A.inet.0: 8 destinations, 11 routes (8 active, 0 holddown, 1 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.0/24 *[BGP/170] 00:10:09, localpref 100 AS path: 64512 I, validation-state: unverified > to 10.10.250.1 via ge-0/0/0.0
Nice – now we’ve got just the one path in our routing table! Let’s double-check that it really is being filtered out of the prefixes we learn from our route reflector:
root@Router_1_PE> show route receive-protocol bgp 4.4.4.4 table CUSTOMER_A.inet.0 192.168.10.0/24 extensive CUSTOMER_A.inet.0: 8 destinations, 11 routes (8 active, 0 holddown, 1 hidden) root@Router_1_PE>
Awesome: it’s no longer there! And look: we have one hidden route. Could that possibly be the route we’re rejecting by import policy?
root@Router_1_PE> show route receive-protocol bgp 4.4.4.4 table CUSTOMER_A.inet.0 192.168.10.0/24 extensive hidden CUSTOMER_A.inet.0: 8 destinations, 11 routes (8 active, 0 holddown, 1 hidden) 192.168.10.0/24 (2 entries, 1 announced) Import Route Distinguisher: 2.2.2.2:2 VPN Label: 299888 Nexthop: 2.2.2.2 Localpref: 100 AS path: 64512 69 69 I (Originator) Cluster list: 4.4.4.4 Originator ID: 2.2.2.2 Communities: target:69:100 target:69:200 origin:64512:1 Hidden reason: rejected by import policy
Well dress me up and call me Barry: we did it! We’re the best!
This site-of-origin community can be used any time you want to reject a prefix that might cause a loop. It’s especially useful in multi-homed topologies, where a LAN might be advertised out of the first WAN link, but then make its way to the other PE that hosts the second WAN link.
PROBLEM FOUR: INDEPENDENT DOMAIN
Once again, let’s have all three of the customer sites live in AS64512.
Imagine our customer turns round and says to us “I don’t want to see AS 69 in my AS-PATH. The number 69 is not, as you claim, “nice”: it’s rude, and I’ll have no rudeness in my network, thank you very much.” Of course, legally this is enough to make any customer contract null and void. That’s definitely true, in all countries. Don’t look it up.
But let’s suppose we want to honour the customer’s request, no matter how wrong they are. Imagine that every customer site had the same AS, 64512, and that the customer doesn’t want to see our AS 69 (nice) in the path. In other words, the customer wants it to seem as if there was an iBGP peering between their sites. Why would they want this? Perhaps to carry BGP attributes that would normally be stripped as it went to the ISP, such as local preference.
To achieve this, we can use a command called independent-domain. This command does something interesting. As far as the CPE is concerned, it now has an internal BGP peering to the ISP, who the CPE sees as being in the same AS as itself, 64512.
But in fact, the ISP is doing something cheeky: it’s taking the BGP prefixes it learns from the CPE, and tunneling the NLRI across the MPLS network, unchanged. As a result, PEs elsewhere in the network can pass on the BGP advertisement unchanged, from the original CPE, onto the CPEs in the rest of the network.
(FUN STORY: I once worked at an ISP where every single customer was configured with independent-domain. I queried why this was, and a senior engineer explained to me that “if you turn it on for just one customer, it breaks every customer.”
Hmm… that doesn’t sound right. So, I tested this in my lab. Initially, VPN Customer A and VPN Customer B were not running independent-domain. I ran a constant rapid ping on our other customer from Customer B’s CPE 1 to Customer B’s CPE 3. While that ping was going, I reconfigured all of Customer A to be independent-domain, which you’ll see in a moment. I checked back on Customer B’s ping… and not a single packet was lost.
So, either that engineer had made a mistake somewhere, or there was a bug in Junos. Which to be fair, isn’t the most outlandish idea in the world. In any case, you can absolutely run some customers as independent-domain, and some without. Which makes sense: if you could only run one or the other then that would be a very strange restriction!)
In a full-mesh MPLS VPN, the config is easy: we just add independent-domain on the relevant VRFs.
In a hub-and-spoke topology though, it’s a little bit trickier. To see why, let’s see what the config on a full-mesh VPN would look like, and then we’ll take a look at how the prefixes are advertised. We’ll use the config on PE 1 as an example. Here’s what the edited VRF looks like:
root@Router_1_PE> show configuration routing-instances CUSTOMER_A instance-type vrf; interface ge-0/0/0.0; route-distinguisher 1.1.1.1:1; vrf-import CUSTOMER_A_IMPORT; vrf-export CUSTOMER_A_EXPORT; routing-options { autonomous-system 64512 independent-domain; } protocols { bgp { group CUSTOMER_A_CPE_1 { type internal; peer-as 64512; neighbor 10.10.250.1; }}}
We also change all the CPE’s BGP peering to a type of “internal”, and we set the peer-as like this:
root@CUSTOMER_A_CPE_1> show configuration protocols bgp group TO_ISP { type internal; export EXPORT_CONNECTED; peer-as 64512; neighbor 10.10.250.0; }
Let’s change the local-preference that CPE 1 advertises to be 666. We’ll edit CPE1’s export policy, which now looks like this:
root@CUSTOMER_A_CPE_1> show configuration policy-options policy-statement EXPORT_CONNECTED { from protocol direct; then { community add ORIGIN_COMMUNITY_CUSTOMER_A_CPE_1; local-preference 666; accept; } }
Below we see that PE 1 learns the prefix as normal. Note the AS path: it’s just internal. And look at our local pref: 666! Delightfully devilish, Seymour!
root@Router_1_PE> show route receive-protocol bgp 10.10.250.1 table CUSTOMER_A.inet.0 CUSTOMER_A.inet.0: 6 destinations, 7 routes (6 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path 10.10.250.0/31 10.10.250.1 666 I * 192.168.10.0/24 10.10.250.1 666 I
As always, let’s follow the 192.168.10.0/24 advertisement. The prefix gets sent to route reflector PE 4, who reflects it to PE 2. PE 2 successfully receives it as iBGP.
root@Router_2_PE> show route receive-protocol bgp 4.4.4.4 table VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB.inet.0 192.168.10.0/24 VRF_CUSTOMER_A_SPOKES_ADVERTISING_TO_HUB.inet.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 192.168.10.0/24 1.1.1.1 100 I
But wait: why is the local pref 100? Didn’t we set it to 666?
Remember, the attributes are being tunneled through the ISP’s network. So yes: in AS69 (nice), the localpref is indeed 100. But when it gets advertised back into AS64512, the localpref is restored:
root@CUSTOMER_A_CPE_2> show route receive-protocol bgp 10.10.250.100 192.168.10.0/24 inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 192.168.10.0/24 10.10.250.100 666 I
There it is: 666. The devil is in the detail!
Now, if this were full-mesh, that would be the end of the story.
However, we’re doing hub-and-spoke. And remember the rule of iBGP: if you learn a prefix, don’t advertise it to other iBGP neighbours. As such, as far as the hub is concerned, it’s now learning prefixes by iBGP – and therefore, it won’t re-advertise them back, because the hub just sees the second peering peering as another iBGP peer. Notice that the only prefixes CPE2 is advertising are its local prefixes:
root@CUSTOMER_A_CPE_2> show route advertising-protocol bgp 10.10.250.102 inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 10.10.250.100/31 Self 100 I * 10.10.250.102/31 Self 100 I * 192.168.20.0/24 Self 100 I
So, how do we go about fixing this. Perhaps we can think of one special situation where the usual rules of iBGP are broken. Hmm… is the special situation perhaps… the Queen’s Birthday? No, silly: I’m talking about route reflectors! Have you ever configured a customer CPE to act as a route reflector? No? Well today’s your lucky day, Susan.
Our new BGP config on the hub CPE looks like this. Let me tell you what we’ve changed: we’ve put both neighbors into the same group, and defined the relevant import and export policies under the individual neighbour. I gave each neighbour a description too, to make it a bit easier to read. But crucially, we add a cluster ID to the group as a whole. And as such, prefixes from one iBGP peer should get re-advertised to the other peer, with the cluster ID attached.
root@CUSTOMER_A_CPE_2> show configuration protocols bgp group TO_ISP { type internal; cluster 69.69.69.69; peer-as 64512; neighbor 10.10.250.100 { description "TO ISP, SPOKE PREFIXES IN"; export POLICY_NOTHING_EXPORTED; } neighbor 10.10.250.102 { description "TO ISP, HUB AND SPOKE PREFIXES OUT"; import POLICY_NOTHING_IMPORTED; export EXPORT_CONNECTED; }}
Did it work? Is the hub CPE 2 now advertising CPE 1’s LAN range back to PE 2? Let’s find out by going straight to CPE 3, and see if it sees anything for CPE 1’s LAN.
root@CUSTOMER_A_CPE_3> show route 192.168.10.0/24 inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.0/24 *[BGP/170] 00:01:53, localpref 666 AS path: I > to 10.10.250.6 via ge-0/0/0.0
Well look at that – indeed it does! And, here’s the magic: the AS-PATH is still fully internal! Our localpref of 666 is even still there. A job well done! Please email my boss and tell him to give me a massive pay rise. I mean MASSIVE.
THAT’S IT!
Boy, we did a LOT of stuff in this post! And we’re not done yet: we’ve not even begun to see what it looks like when the customer wants to run OSPF instead of BGP. Stay tuned, because in a future post we’ll roll up our sleeves and do exactly that. By the time we’re done, we’ll be so good at hub-and-spoke MPLS VPNs that our middle name will be Hubandspoke. Which sucks, because that’s a terrible middle name. But sadly, we don’t have a say in it. It’s going to happen, regardless of whether we want it. Truly, this is the burden of the network engineer.
As always, if you enjoyed this post, I’d love you to share it on the social media of your choice, so that your friends and colleagues can learn some cool new stuff. The more people read the posts, the more I’m inspired to write even more.
If you’re on Mastodon, follow me to find out when I make new posts. (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.)
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.


